Une des utilisations principales de l’informatique de nos jours est le traitement de quantités importantes de données dans des domaines
très variés :
- un site de commerce en ligne peut avoir à gérer des bases de données pour des dizaines de milliers d’articles en vente, ses clients,ses commandes
- un hôpital doit pouvoir accéder efficacement à tous les détails de traitements de ses patients
- un etablissement scolaire doit gerer l'ensemble de ses élèves, de son personnel, etc …
-
Les données
-
L'information
Les données structurées
Accès aux données
Le format CSV
Exercice
Les données sont des ensembles de symboles (mots, nombres, images, sons etc...) pour représenter le monde réel
(objets, événements, etc...).
Elles peuvent être quantitatives ( âge, poids, taille, température,..) ou qualitatives ( nom,prénom,adresse,statut,...)
Une information est une donnée interprétée.
Prenons la donnée suivante : 2 81 12 92 01208680. C'est juste une série de chiffres...
Si maintenant on précise que c'est un numéro de sécurité sociale, on en déduit qu'il s'agit de celui d'une femme née en 1981 au mois
de décembre dans le département 92 (haut de seine).
Une information = des données + un modèle d'interprétation.
Reprenons le cas de la série de chiffres : 2 81 12 92 ...., si on ne précise pas que c'est un numéro de sécurité sociale,
ce n'est qu'une série de chiffres.
Les données doivent être décrites, par un champ ou descripteur compréhensible pour celui qui veut les interpréter.
Prenons le cas d'une bibliothèque, et considérons un abonné. Lors de son inscription celui-ci fournit des données (son nom, son prénom,
son adresse et son numéro de téléphone), ces données seront associées aux descripteurs (Nom, Prénom, Adresse, n-tel).
On enregistre les données des abonnés dans une table , avec les mêmes descripteurs, on crée ainsi
une collection.
On regroupe ensuite toutes les collections ( livres, abonnés, emprunts, etc...) dans une base de donnée.
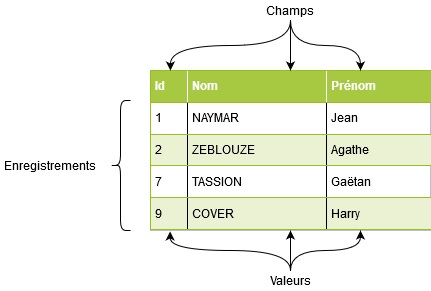
Organisées en table, les données se présentent sous la forme suivante :
Certaines sont accessibles à tous ( Open Data comme le site data.gouv.fr) et d'autres sont non accessibles( privées ou sensibles).
Certaines bases de données sont souvent comparées à l'or noir d'internet. Les données qu'elles contiennent sont utilisées pour analyser le
comportement des internautes afin de leur proposer tel ou tel produit lors de leur navigation.
De puissants algorithmes sont utilisés pour faire ces interprétations.
Avec le développement de L'IA, les données sont nécessaires pour construire les modèles d'apprentissage.
Le format CSV (pour Comma Separated Values, soit en français valeurs séparées par des virgules) est un format très pratique pour représenter des données structurées.Dans ce format, chaque ligne représente un enregistrement et sur une même ligne, les différents champs de l’enregistrement sont réparés par une virgule (d’où le nom). En pratique, on peut spécifier le caractère utilisé pour séparer les différents champs et on utilise fréquemment un point-virgule, une tabulation ou deux points pour cela.
Aller sur le lien suivant du site data.gouv.fr lien et récupérer le fichier en .csv
Ouvrir ce fichier avec le bloc-notes, puis libre office et répondre aux questions suivantes :
Quel est le séparateur utilisé ?
Comparer la 1ère ligne aux autres lignes ?
Combien de descripteurs ?
A retenir :
Les fichiers CSV sont donc des fichiers textes dont les données sont séparées les unes des autres par un séparateur (; ou , ou tabulation, ou ce que vous voulez).
Chaque ligne du fichier contient
un jeu de données.
On a donc au final des lignes et des colonnes définies par le séparateur et les retours à la ligne.
Dans la suite on utilisera le fichier countries.csv à télécharger et ouvrir dans un éditeur de texte
pour observer sa stucture
Notre première action sur ce fichier CSV sera de l'importer et le transformer en une structure de Python